Introduction to Depth Of Field - Part I

Depth of Field (DOF) is a popular effect, used to convey a sense of of depth to a large scene, or in some cases, used as an artistic tool to transmit certain emotions and to alter the composition of a scene.
Anatomy of Depth of Field
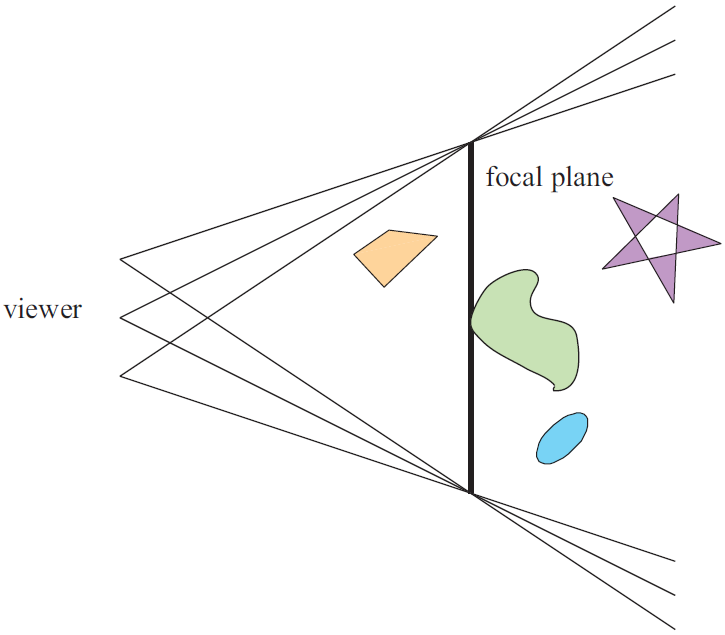
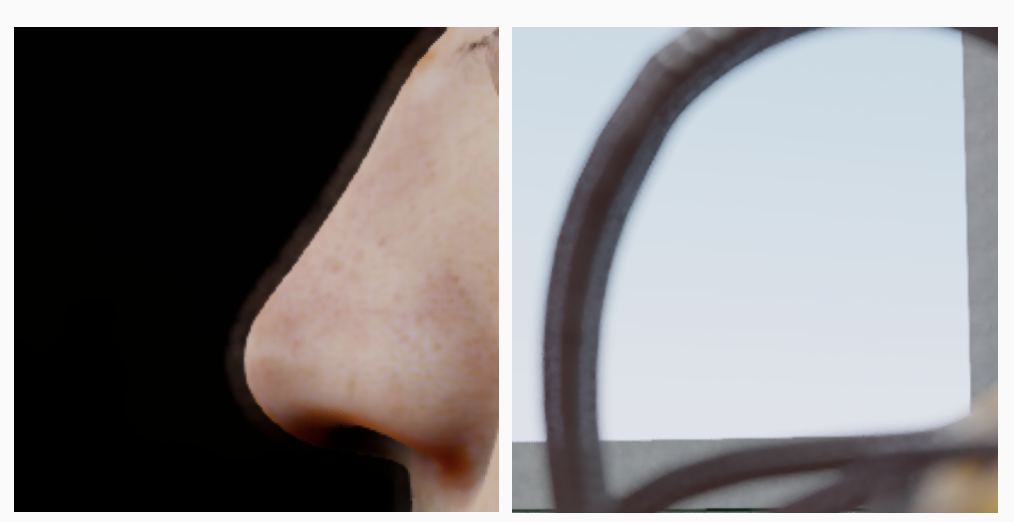
As the term “depth of field” intuitively suggests, it describes the range of distances from the camera within which objects appear sharp and fully in focus (Figure 1). Areas positioned closer or farther away than this range become progressively blurred. Before diving deeper into the computational methods and graphics implementations, let’s take a moment to explore how DOF occurs naturally in physical cameras .

Real-world Cameras and DOF
To understand DOF intuitively, we should briefly examine the two key physical components of real cameras: the image sensor and the lens.
The image sensor is essentially a flat, two-dimensional grid composed of millions of tiny, light-sensitive pixels. Each pixel collects incoming photons (particles of light), converting them into digital signals that computers or other digital devices process and store as images1
The lens is equally crucial. Its main role is to bend (or refract) incoming light rays, much like the human eye does. Imagine the lens as a carefully shaped piece of glass designed to redirect parallel incoming rays of light to converge precisely onto a single point on the image sensor. Without a lens, these rays would scatter randomly across the sensor, resulting in blurry and indistinct images. Different types of lenses can converge or diverge rays differently, creating diverse visual effects, but the core principle remains consistent.
In real cameras, the DOF range primarily depends on three key parameters2 3:
- Aperture: The diameter and shape of the camera’s opening.
- Focal Length: The distance from the lens to the image sensor (often called the “film-back”).
- Focal Distance: Distance from the center of the lens to the real-life desired subject.
Aperture and its Impact on DOF
The aperture refers to the size of the camera’s opening through which light enters. In physical terms, the aperture is controlled by an adjustable mechanism known as the diaphragm, consisting of multiple overlapping blades arranged in a circular shape. By opening or closing these blades, photographers control how much light enters the camera.
Aperture is measured in F-stops, which have an inverse relationship to the diameter of the camera’s opening (Figure 2):
- Lower F-stop values correspond to larger apertures (wider openings), allowing more light to enter. Larger apertures result in shallower DOF, creating more pronounced blur effects in the foreground and background.
- Higher F-stop values correspond to smaller apertures (narrower openings), letting in less light but producing sharper images over a larger range of depths, thus less blur overall.

Reducing the aperture diameter (increasing F-stop) narrows the cone-shaped paths of the incoming rays. This narrower cone makes it easier for rays originating from different distances to converge closely enough to form a sharper image. At the extreme limit, if the aperture was infinitely small (like a pinhole camera—a theoretical camera model where the aperture is reduced to a tiny pinhole, allowing rays from nearly every distance to converge sharply4), you would achieve almost infinite DOF. However, smaller apertures admit less light, potentially causing underexposed (dark) images. Correcting this underexposure through longer exposure times can lead to unwanted motion blur or grainy noise artifacts.
Conversely, wider apertures result in broader cones of incoming rays, increasing divergence and blurring out-of-focus points into a circular shape on the image sensor. This blurred circle has a formal name in photography and rendering: the Circle of Confusion (CoC). All of these concepts will be touched upon in the chapters that will follow.
Focal Length and Zooming
The focal length describes the distance from the center of the lens to the image sensor (film-back), typically measured in millimeters (usually ranging from 50mm to 100mm). Adjusting the focal length essentially moves the sensor closer to or further away from the lens, changing how “zoomed-in” or “zoomed-out” the resulting image appears. Increasing the focal length (zooming in) narrows your field of view, emphasizing the blur effect in the out-of-focus regions (Figure 3).
Focal Distance (or Focal Plane)
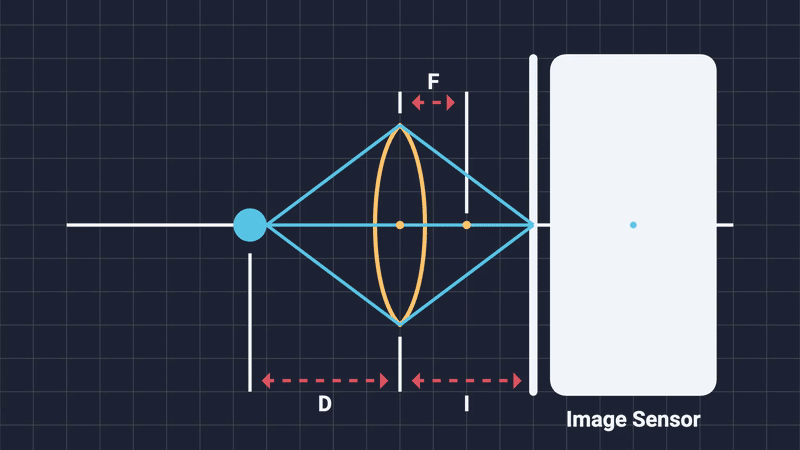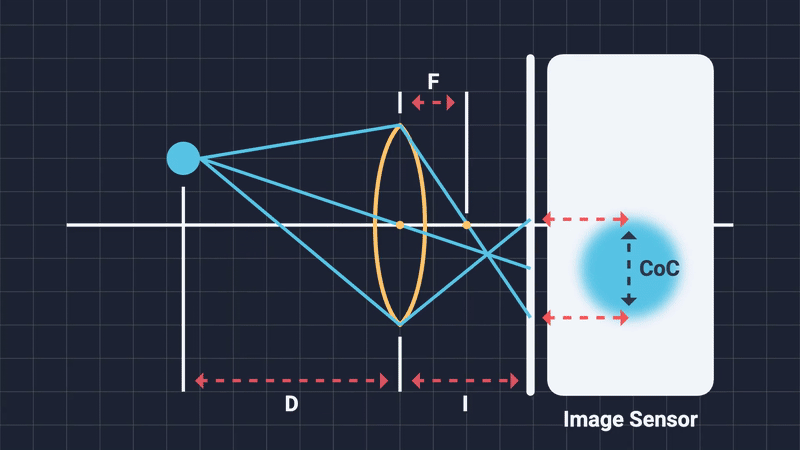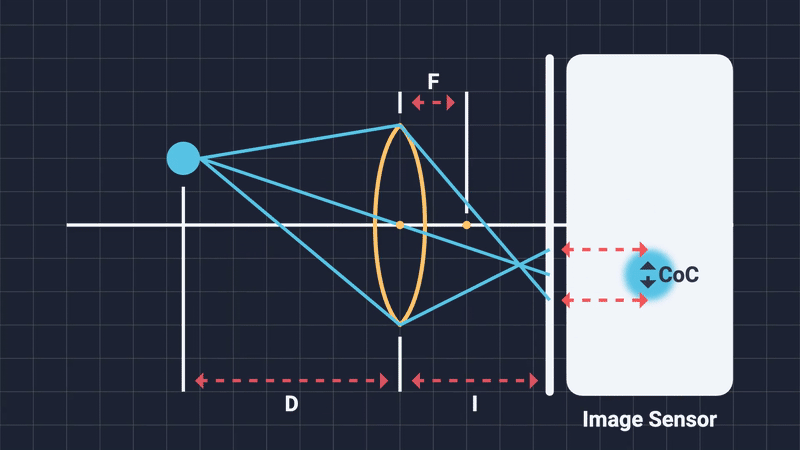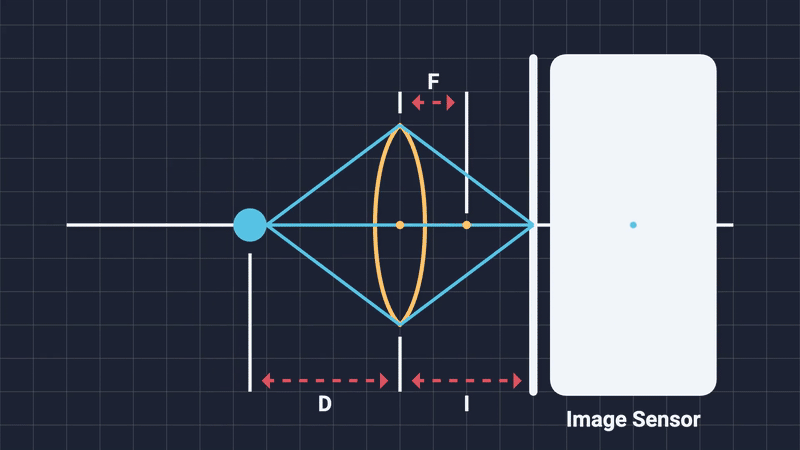
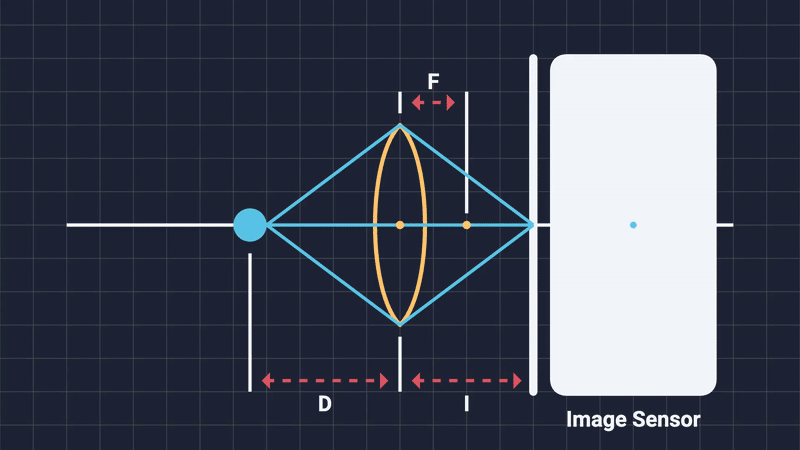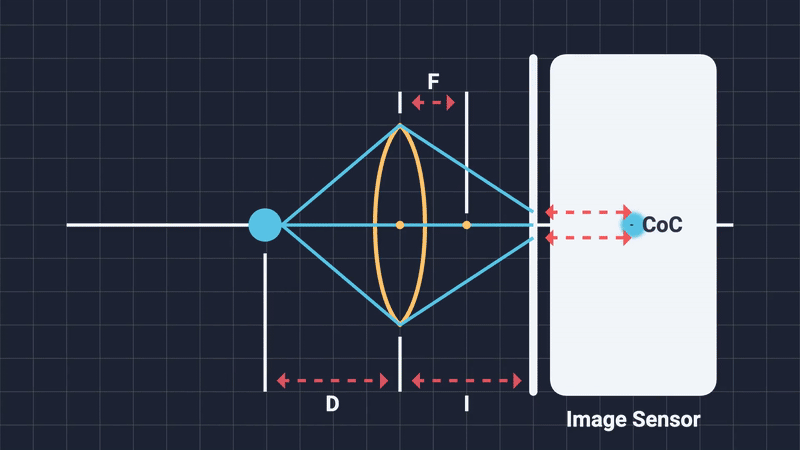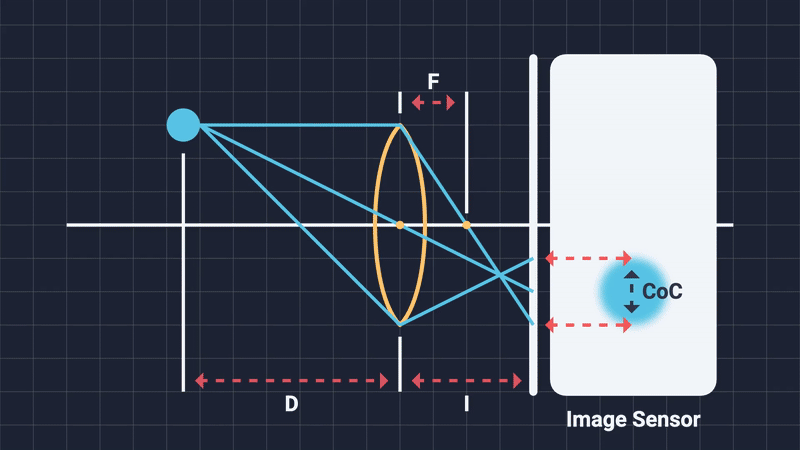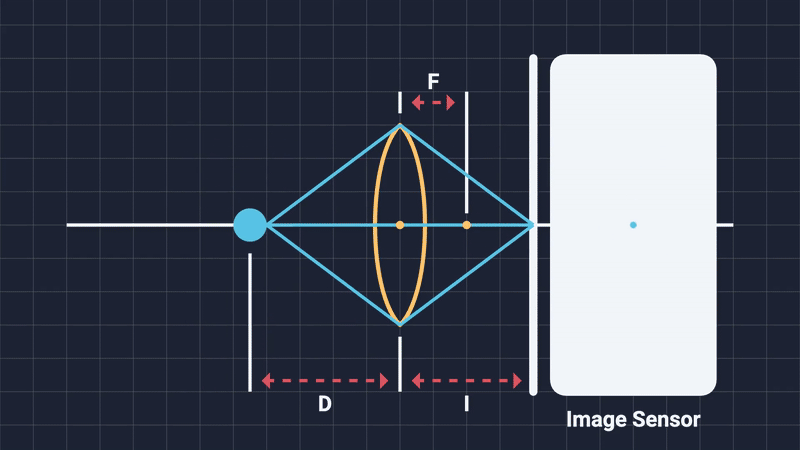
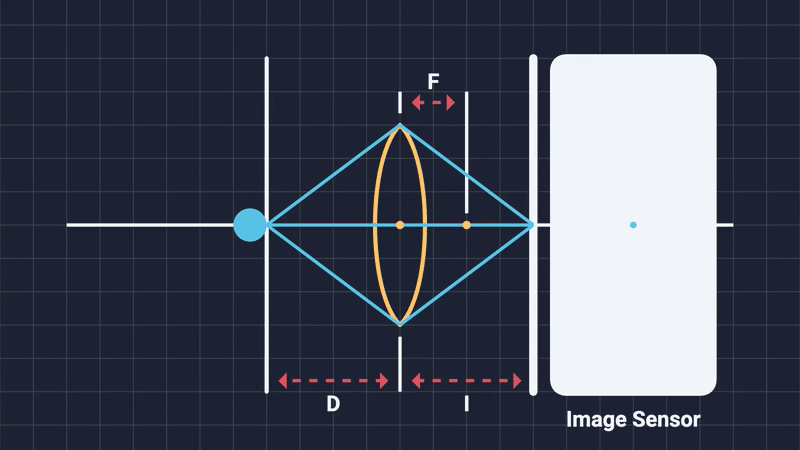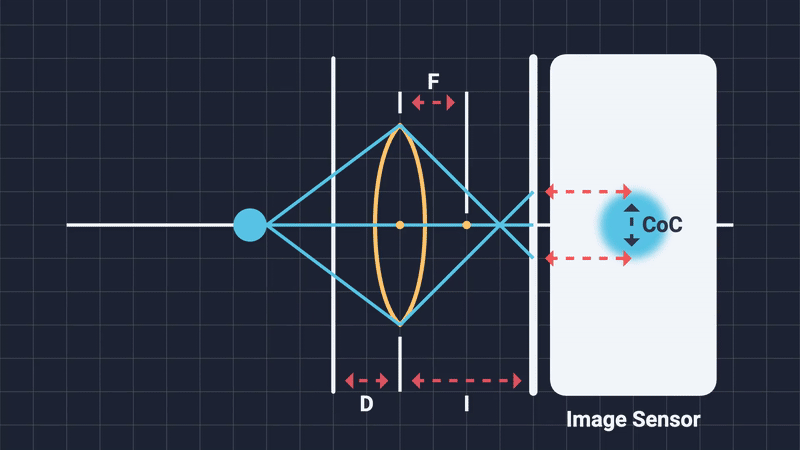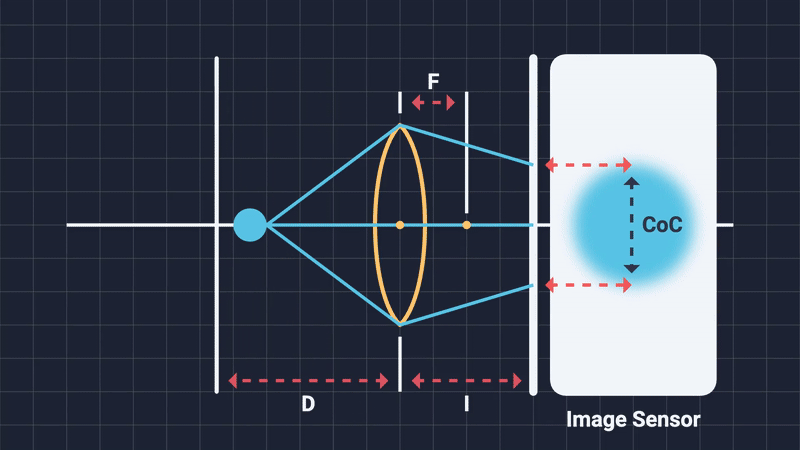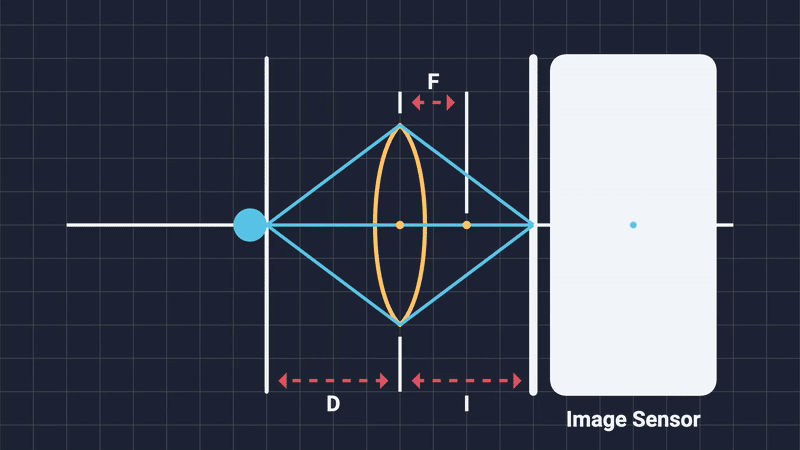
The focal distance is simply the distance from the center of the camera lens to the subject of the shot. Changing it will alter what objects are considered in-focus and which are out-of-focus. Think of it as moving an imaginary plane on the camera’s forward direction. Any object that is on or close to this imaginary focal plane, will be in-focus. Anything outside the DOF range will be blurred (Figure 4, 5).
Circle of Confusion
When out-of-focus objects project onto the sensor, their light rays do not neatly converge to a single point. Instead, these rays spread evenly across an area, creating a uniformly illuminated circular spot known as the Circle of Confusion (Figure 6). The shape of this circle depends on the diaphragm blades: more expensive cameras, having more blades, produce smooth, nearly perfect circles; cheaper cameras with fewer blades produce polygons, often pentagonal or hexagonal shapes. This phenomena is known as “bokeh” (Japanese word for blur) and it refers to the distinctive geometric shapes with which are high in local contrast that are mostly visible in the out-of-focus regions of the image (Figure 7).
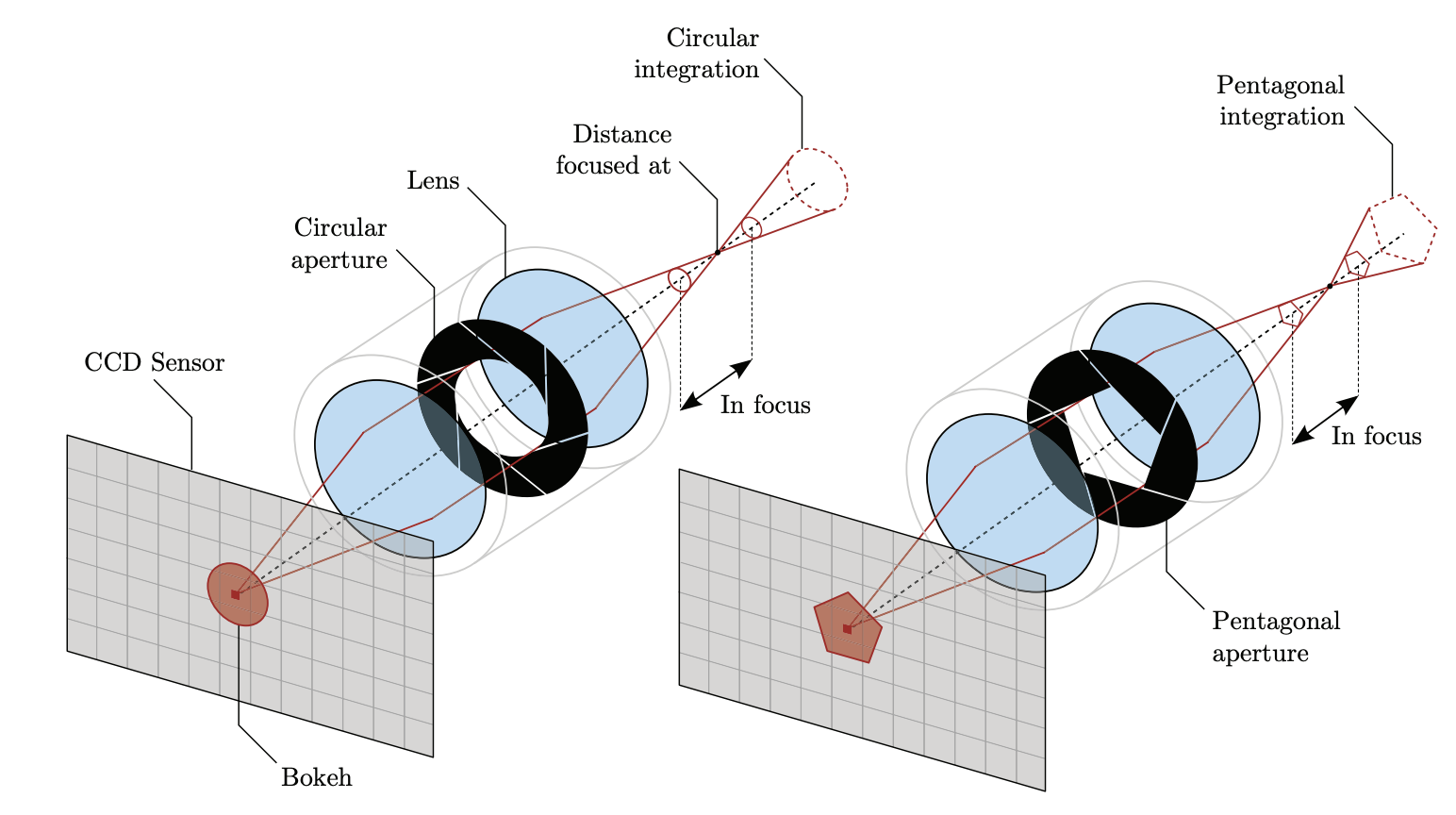

The diameter of the CoC (measured in pixels) provides a practical measure of blur intensity, and hence, the DOF is formally defined as the range within which the CoC remains acceptably small5:
- CoC diameter smaller than one pixel: points appear sharp and in-focus.
- CoC diameter greater than one pixel: points blur increasingly as diameter expands.
From Real Cameras to Computer Graphics
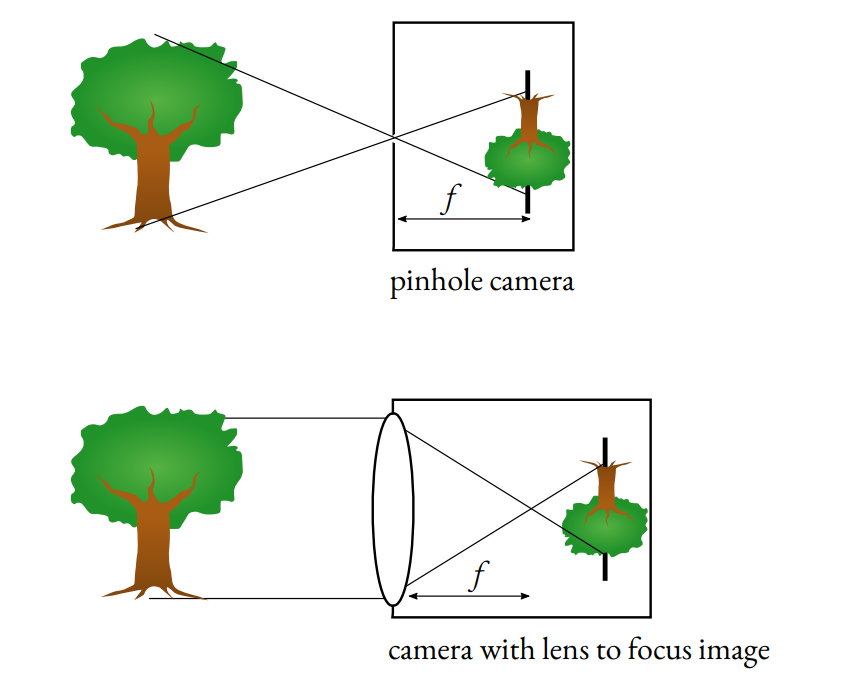
In computer graphics, the virtual cameras we typically use are based on a simplified theoretical ideal camera model—the pinhole camera. As mentioned earlier, a pinhole camera has an infinitesimally small aperture (just a point), allowing rays from any distance to converge sharply onto the sensor, resulting in theoretically perfect focus across infinite depth (Figure 8). This model is just a first order approximation of the mapping from 3D to 2D scenes, because it does not take into consideration lense properties such as geometric distortions or blur.
However, since real cameras don’t behave like perfect pinhole cameras, we need computational methods to approximate real-world blur effects. Besides the accumulation buffer method and raytracing, most techniques do this through the approximation of the CoC value. Two common approaches exist:
- Physically Accurate CoC: Derived directly from the camera parameters through equations such as the Thin Lens Equation6 (Figure 9).
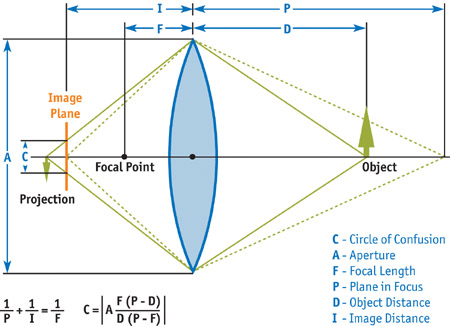
float coc = abs(aperture * (focallength * (objectdistance - planeinfocus)) / (objectdistance * (planeinfocus - focallength)))
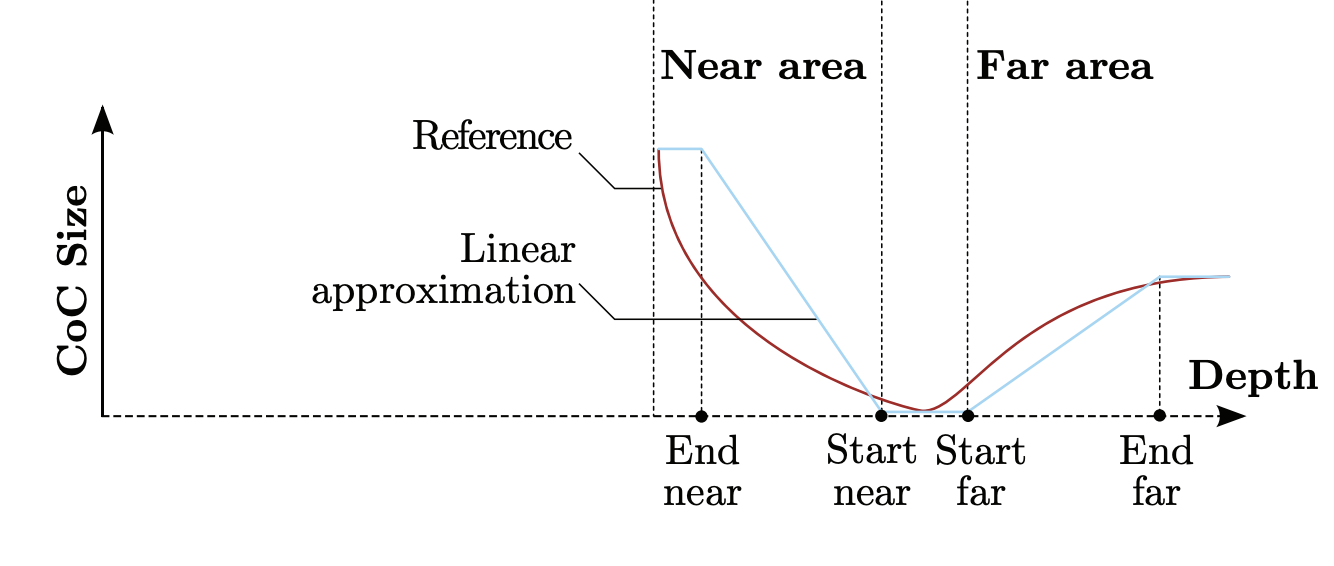
- Linear Approximation: CoC value approximated through a linear function and clamped using Z-buffer values between user-defined bounds7 (Figure 10).
float4 PSMain(PS_INPUT input): SV_Target
{
float depthNDC = depthBufferTexture.Sample(pointClampSampler, input.texCoord).x;
float depth = DepthNDCToView(depthNDC);
float nearCOC = 0.0f;
if (depth < nearEnd)
nearCOC = (depth - nearEnd) / (nearBegin - nearEnd);
else if (depth < nearBegin)
nearCOC = 1.0f;
nearCOC = saturate(nearCOC);
float farCOC = 1.0f;
if (depth < farBegin)
farCOC = 0.0f;
else if (depth < farEnd)
farCOC = (depth - farBegin) / (farEnd - farBegin);
farCOC = saturate(farCOC);
return float4(nearCOC, farCOC, 0.0f, 0.0f);
}
In practice, CoC values are represented in a range (-1, 1), signifying their relative position to the focal plane:
- Negative values correspond to the Near Field (closer to camera).
- Values around zero represent the Focus Field.
- Positive values correspond to the Far Field (further from camera).
Methods for Rendering DOF
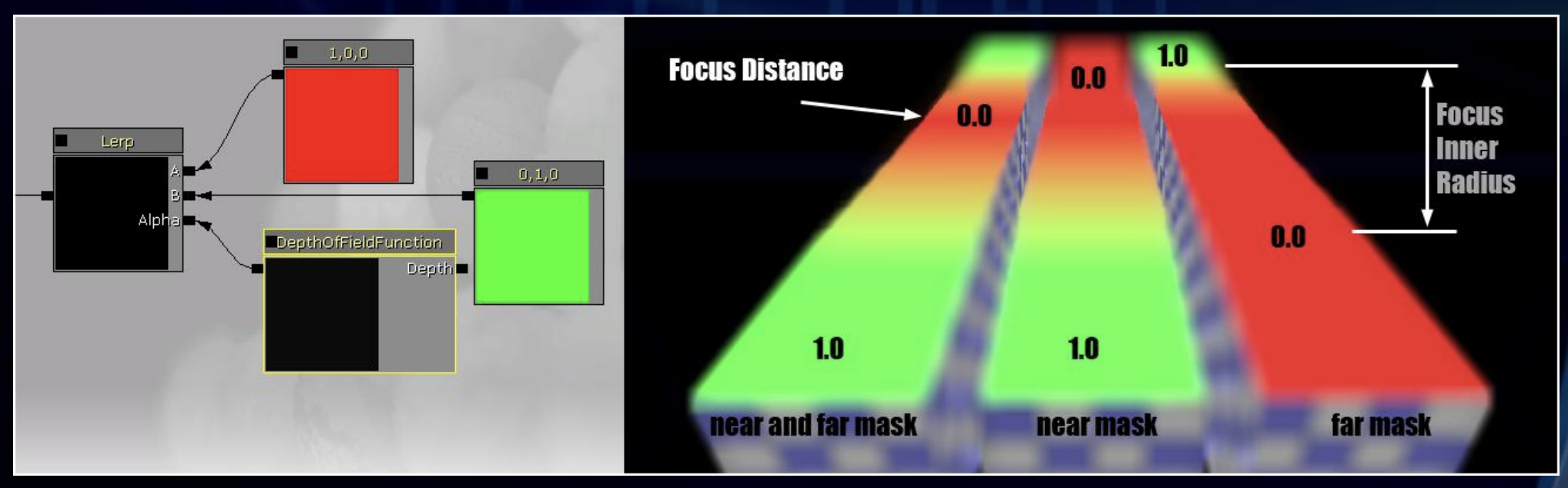
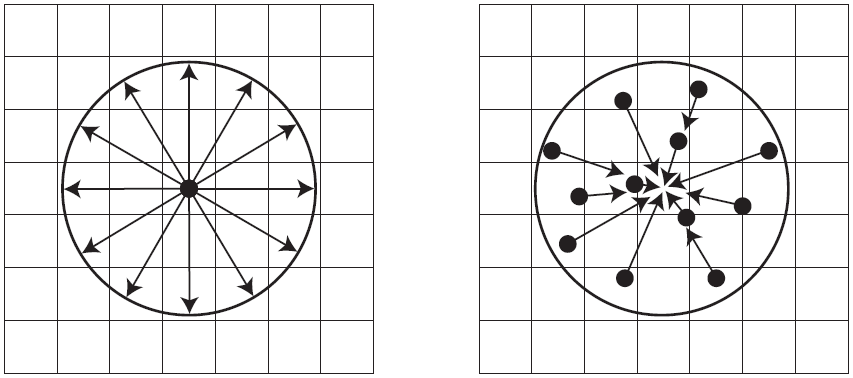
To efficiently render DOF effects, graphics pipelines generally separate the image into layers based on their CoC:
- Focus Field: Near the focal plane (sharp, CoC < 1px).
- Near Field: Closer than the focal plane (blurred foreground).
- Far Field: Farther away than the focal plane (blurred background).
Rendering these layers separately simplifies handling different blending behaviors:
- Near Field: Requires blending transparency at edges (semi-transparent blur).
- Far Field: Must avoid haloing around sharp objects, handled carefully.
Most methods follow this workflow (also see Figure 11):
- Calculate per-pixel CoC from depth buffer.
- Split image into layers using CoC masks.
- Downsample and apply blur to layers independently.
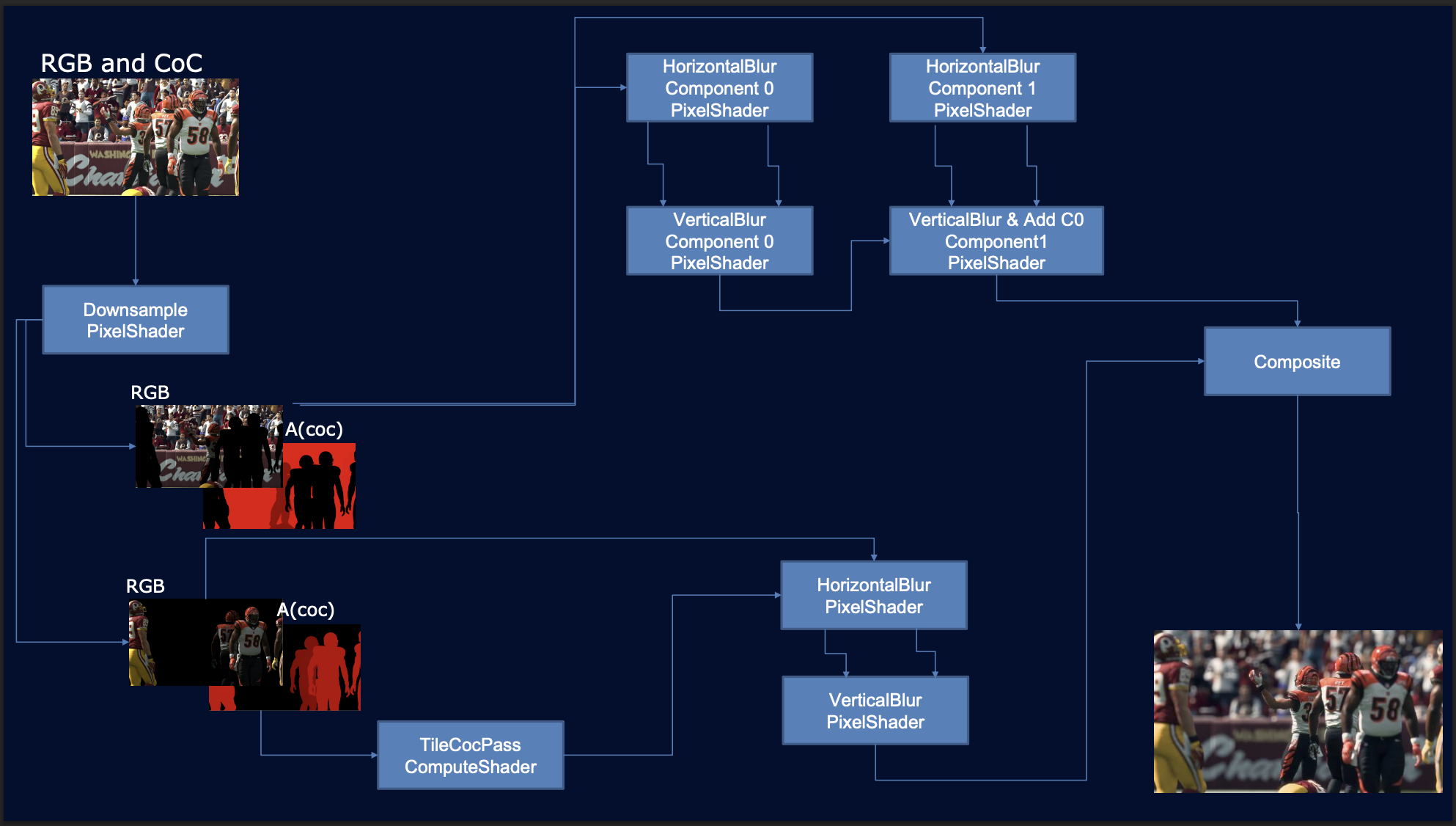
In subsequent chapters, we explore various DOF rendering techniques—including Scatter-Based, Gather-Based, and Scatter-As-You-Gather methods—in greater detail.
Simulating DOF (Ground Truth)
To truly understand and evaluate DOF rendering methods in computer graphics, it was important to have a reliable reference—a sort of “ground truth” to compare against. Such a ground truth could be simulated accurately using an approach known as the Accumulation Buffer (AB) method. An AB is just a high precision color buffer that is used to store multiple images inside of it6 8.
Imagine you’re holding a real camera, focusing precisely on an object placed at a certain distance—the focal plane. If you slightly move the camera around this focal plane while always keeping it pointed directly toward it, you’ll notice something interesting:
- Objects exactly on or near the focal plane stay relatively sharp because their position relative to the sensor doesn’t change significantly.
- Objects far away from this plane (either closer or further) shift more dramatically across your sensor from one camera position to another. As you average these multiple views, these areas naturally blur.
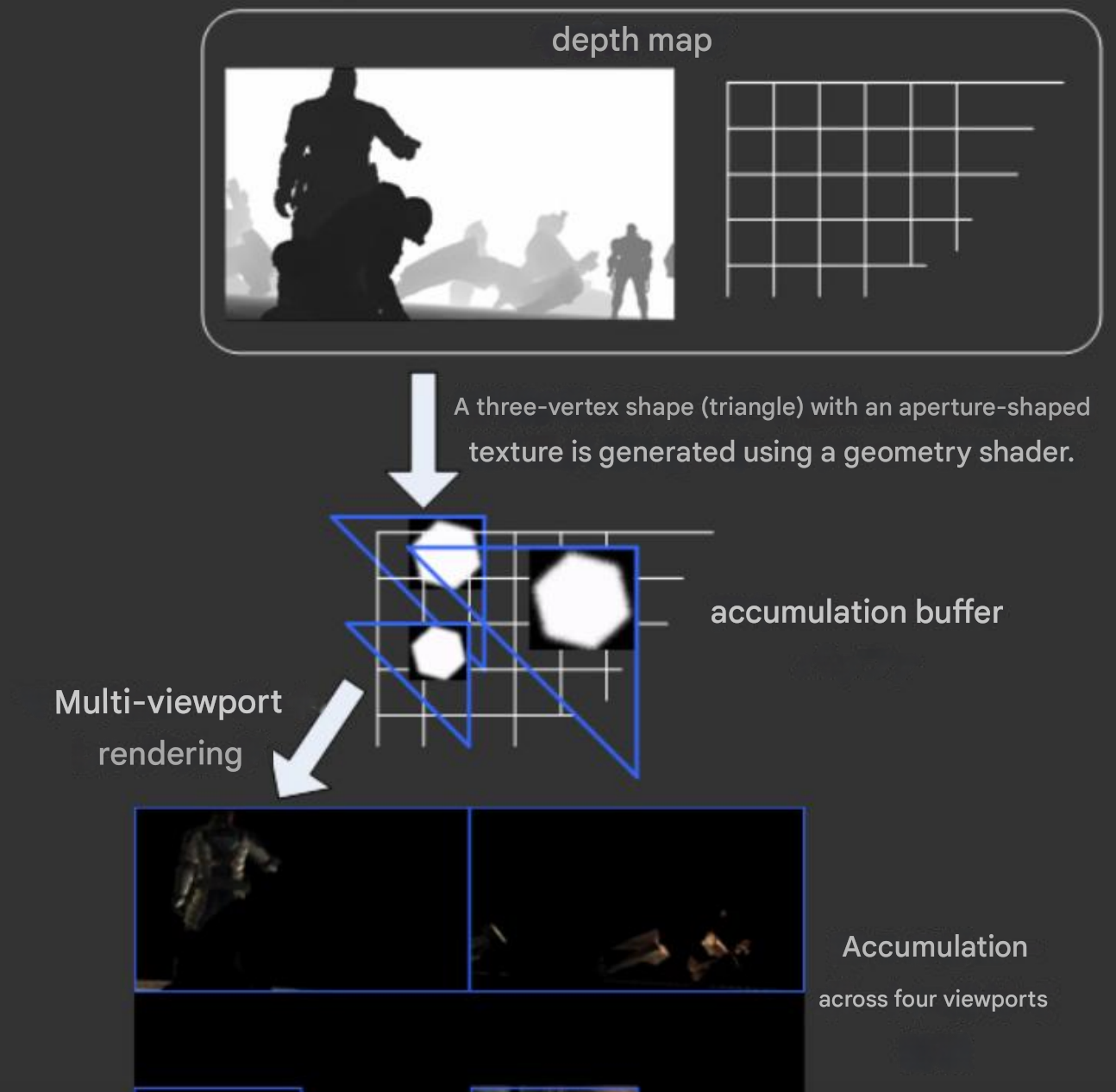
In the world of computer graphics, the Accumulation Buffer method digitally replicates this intuitive physical process. The focal plane stayed fixed, and the virtual camera’s position is moved slightly multiple times, each time capturing a snapshot of the scene from these different viewpoints (Figure 12). These snapshots are then combined—summed up and averaged—to produce the final image.
The more snapshots or samples taken, the closer the resulting image is to real-world accuracy. A limited number of snapshot can result in ghosting, just straight up copying of objects, or bending artifacts when high blur is present. As a rule of thumb, you can estimate the number of accumulation passes required for realistic DOF by dividing the area of the largest CoC by the number of pixels you’re willing to tolerate per sample. For high-quality results with minimal banding (limited to about 2×2 pixel blocks), aim for one pass per 4 pixels of CoC area—for example, a CoC with an 8-pixel radius (≈200 pixels in area) would require about 50 passes (200 /4). For a more performance-friendly but lower-quality approximation, you can stretch that to one pass per 9 pixels of CoC area, tolerating up to 3×3 pixel blocks of blur and reducing the pass count significantly—for instance, down to about 12 passes for a 6-pixel-radius CoC. This trade-off between visual fidelity and rendering cost is key when tuning for real-time vs. offline rendering6. Consequently, there is a significant cost: rendering each viewpoint separately means that this technique is computationally expensive. Because of this, the accumulation buffer method is rarely used directly during real-time rendering. Instead, it serves as a reliable benchmark, allowing developers and artists to qualitatively compare and refine faster but less physically accurate DOF approximations.
All subsequent rendering methods we discuss attempted to approximate this accurate simulation in different ways—each exploring and solving the DOF problem from various perspectives, especially in terms of efficiently approximating the CoC.
Scatter-Based (Forward Mapping) Method
In scatter-based DOF techniques, each pixel scatters its shading value to its neighbours. Unfortunately, scattering operations do not map well to current shader capabilities as it requires some level of synchronisation that would affect the parallel nature of GPUs. One solution that worked well in practice is the usage of sprites. Each out-of-focus pixel is transformed into a sprite—a piece of geometry, typically a rectangle or circle, with a texture attached to it —that represents how much that pixel should blur across the screen. The size of this sprite is driven by the CoC, a value derived from the z-buffer.
To build an intuition, imagine a white square the size of 1 pixel floating in 2D space. If that pixel is in focus, it stays sharp—affecting only its original screen-space location. We now take that tiny white quad and scale it up using the CoC value, spreading it in nearby pixels. The result? Its contribution overlaps neighboring pixels.
So rather than computing blur by pulling in nearby samples (as in gather-based methods), each pixel scatters its own influence outward, like dropping a pebble and watching ripples expand.
In practice, this is often implemented using a Geometry Shader, a programmable stage in the GPU pipeline that can dynamically emit geometry based on input data. Here, it reads the pixel’s depth, calculates its CoC, and then emits a triangle-based sprite, scaled accordingly9 (see Figure 13).
Geometry information of the sprite is then sent to a Pixel Shader (PS), where a custom bokeh texture is sampled, and each sprite rasterised and blended into the final image using additive alpha blending. Additive blending combines the colors of overlapping sprites, creating a cumulative blur effect. Finally, these sprites are composited into a single coherent image by averaging, normalizing, and upscaling the resulting blurred layers.
This process is intuitive and straightforward: it is called “scattering” because each blurred pixel scatters its influence outward onto surrounding pixels. However, the scatter-based method faces significant challenges when executed on GPUs:
Graphics Processing Units (GPUs) are designed around massive parallelisation—running thousands of threads simultaneously to render images rapidly. This parallelism relied on threads operating independently with minimal synchronisation. Scattering is equivalent to a write operation, however, doing so on GPUs require multiple threads to coordinate frequently, as they have to write results to overlapping pixel locations simultaneously, causing synchronisation bottlenecks10. This is partially solved through the usage of sprites, however, the variability in performance yielded by such methods makes them less suitable for real-time applications11. This variability is mostly given by the high fill rate and bandwidth required by drawing a quad for each pixel7.
Scatter-based methods are notoriously tricky when combined with other translucent effects such as smoke, fog, or particle systems. Since each of these effects also involved transparency and blending, compositing them with scatter-based DOF methods became complicated. Often, developers had to give artists explicit control over the order in which different effects or materials were composited12 (e.g., DOF before or after particles), adding complexity and additional time to the artistic workflow (Figure 14)
Gather-Based (Backward Mapping)
To better understand the gather-based method, let’s first revisit briefly what we learned about scatter-based (forward mapping) methods. Recall that in scatter-based methods, each pixel “spreads” its blur to nearby pixels. While straightforward conceptually, this isn’t very GPU-friendly due to synchronization complexities.
Gather-based methods, on the other hand, flip this logic upside down. Instead of scattering, each pixel “gathers” or collects information from neighboring pixels around it (Figure 15). Imagine you’re trying to figure out the exact shade of color your pixel should be. Instead of telling your neighbors, “Here’s my blur!”, you ask your neighbors, “What blur should I be seeing here?” This subtle yet important inversion aligns very naturally with GPU architectures because GPUs excel at sampling data from nearby memory locations. Sampling nearby pixels—essentially reading memory that’s close together13—is exactly the kind of task GPUs do exceptionally efficiently . This hardware capability makes gather-based approaches attractive from both a performance and implementation standpoint
Most of GPUs and Graphics APIs offer the option for hardware-based gather operations on GPU resources (e.g. textures). Check the code for an example written in HLSL.
float4 samples = myTexture.GatherRed(mySampler, uv + float2(0.5f, 0.5f) / myTextureDim);
float r1 = samples.w;
float r2 = samples.z;
float r3 = samples.x;
float r4 = samples.y;
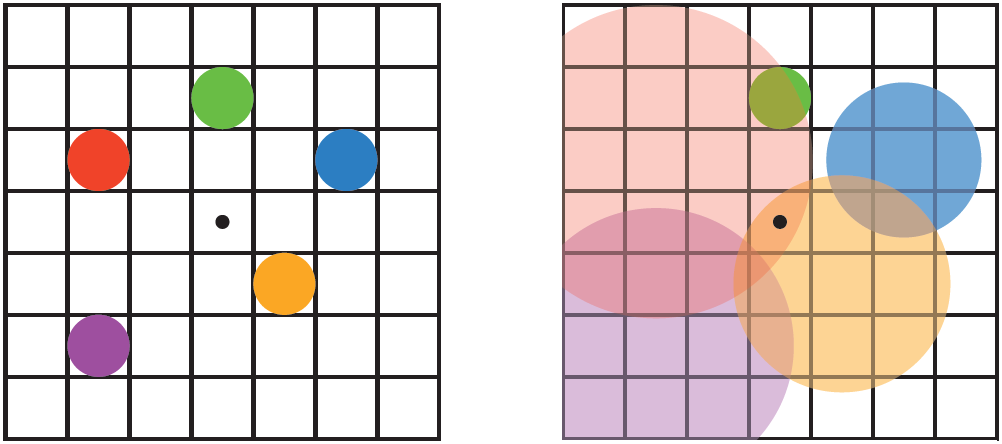
The unfortunate aspect about these methods is the Neighborhood Assumption. Gathering inherently assumes that neighboring pixels have similar depth values, meaning they’re part of the same object or closely related objects. However, at object boundaries—where depth values shift drastically—this assumption can break down, leading to visible artifacts like haloing.
Let’s visualize this haloing effect intuitively: imagine you’re sampling colors for a pixel at the edge of a in-focus foreground object. Some gathered samples accidentally include background pixels due to a large CoC radius. Blending these distant pixels creates unwanted halos around the object’s edge, breaking visual realism (Figure 16).
Gather-based (backward mapping) methods elegantly leverage GPU strengths by shifting complexity away from scattering information to intelligently gathering it. While highly efficient and broadly effective, handling edge cases at object boundaries remains a nuanced challenge, necessitating careful management of sampling strategies and edge-aware filtering techniques.
Scatter-as-you-Gather (Hybrid Method)
We’ve previously discussed two distinct approaches for rendering DOF: the Scatter-Based method, where each pixel actively spreads its color to neighboring pixels, and the Gather-Based method, where each pixel passively pulls colors from its neighbors. Each approach comes with its unique advantages and inherent limitations. Interestingly, there’s a clever hybrid approach—often called the Scatter-as-you-Gather method—that blends the strengths of both these worlds.
To combine the efficiency of gathering with the precision of scattering, we use a hybrid method: scatter-as-you-gather. This method smartly flips the scattering problem on its head. Instead of each pixel blindly pushing its color outward, pixels carefully examine their neighbors and selectively decide whether a neighbor’s color should “scatter” into them11 14.
Here’s an intuitive breakdown of the process (see Figure 17 and Figure 18 for a visual overview):
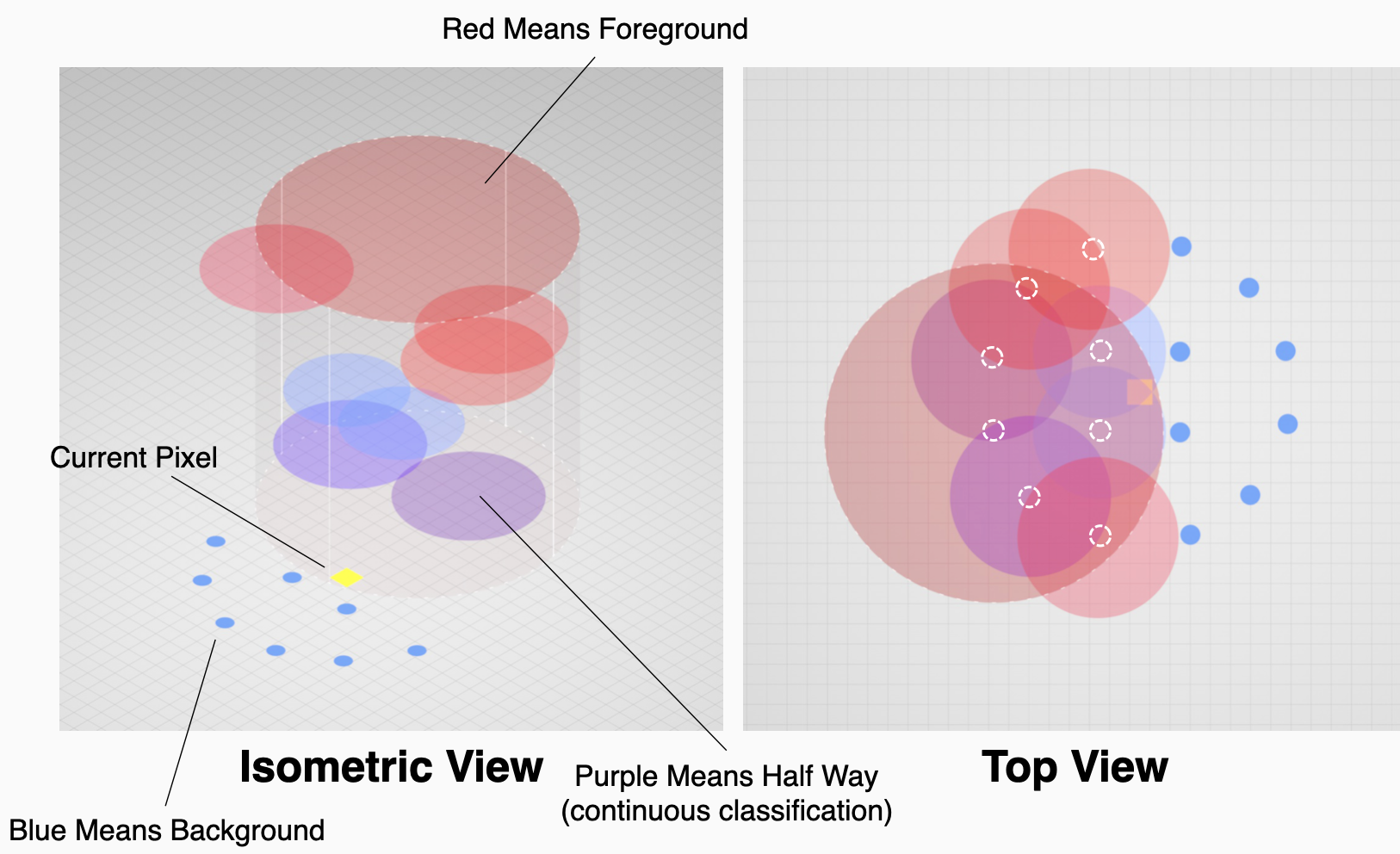
- Gather Phase: For each pixel, we first gather color and depth information from neighboring pixels within a radius defined by the current pixel’s own CoC. Remember, the CoC size indicates how blurry a pixel should appear—the larger the CoC, the more blurred the pixel.
- Scatter Decision (Depth-Based Selection): After collecting these neighboring pixels, the algorithm evaluates each neighbor’s own CoC to determine if and how their blurred color could affect the current pixel. Think of this as each pixel “asking” its neighbors: “Does your blur overlap with my location?”. To resolve conflicts—where multiple neighboring pixels potentially scatter into one pixel—the algorithm prioritizes by depth: the pixel closest to the camera (lowest z-depth) is chosen as the near image. Remaining neighbors close in depth to the neighbor with lowest z-depth are combined using alpha-blending, averaged together and stored in a foreground texture. Blending pixels in this manner gets rid of the need for sorting based on depth (which is a common performance bottleneck)
- Background Layering and Final Composition: Pixels that do not significantly scatter into our current pixel (usually those further back or less blurry) are grouped into a separate background layer. Finally, the carefully crafted foreground layer is composited over this background layer using alpha blending to produce the final, visually coherent result.
So, to summarize:
- Reduced Haloing and Edge Artifacts: By carefully selecting neighboring pixels based on their CoC and depth, this method reduces problematic halos around objects. It’s particularly effective in rendering realistic transitions between blurry foreground objects and the sharp focus region behind them.
- Efficient GPU Implementation: Although the method introduces an extra complexity step—evaluating neighbors—it remains highly compatible with GPU architectures. GPUs excel at independent gather operations, and this hybrid approach leverages that strength while mimicking scattering through a carefully controlled selection process.
- No Need for Depth Sorting: Traditional scatter-based methods might require sorting pixels to correctly composite translucent layers—a computationally expensive process. The hybrid method sidesteps this requirement entirely through smart alpha blending, achieving visually accurate results without performance hits.
Despite its strengths, this method isn’t without trade-offs. The shader logic can become quite intricate, especially when handling edge cases involving large blur radii or dense depth discontinuities. More blur means more neighbors to evaluate, which can add up computationally. In practice, optimizations or approximations are often needed to maintain performance in high-CoC scenarios.
Final Thoughts and Next Steps
Depth of field is one of those cool effects that combines photography and code in a way that’s both approachable and satisfying—especially if you’re new to computer graphics. My goal with these posts is to make graphics more accessible, and DOF is a great beginner-friendly starting point. Stay tuned for part two, where I’ll dive into implementing one of these methods step-by-step. If you enjoyed this and want to help support more rendering blogs, you can help me with a coffe!
References
LUCID Vision Labs - Understanding The Digital Image Sensor ↩︎
Matt Pharr and Greg Humphreys. Physically Based Rendering, Second Edition: From Theory To Implementation, Second edition. San Francisco, CA: Morgan Kaufmann Publishers Inc., 2010. ↩︎
GPU Gems 3 - Chapter 28. Practical Post-Process Depth of Field ↩︎
GPU Gems 1 - Chapter 23. Depth of Field: A Survey of Techniques ↩︎ ↩︎ ↩︎
GPU Zen: Advanced Rendering Techniques, by Wolfgang Engel ↩︎
Bokeh depth of field – going insane! part 1, by Bart Wronski ↩︎
GPU Gems 2 - Chapter 32. General Purpose Computing GPUS Primer ↩︎
Real-Time Rendering, 4th Edition, by Tomas Akenine-Möller ↩︎ ↩︎
The Technology Behind the DirectX 11 Unreal Engine “Samaritan” Demo, by Martin Mittring et. al ↩︎
Nocentino, Anthony E., and Philip J. Rhodes. “Optimizing memory access on GPUs using morton order indexing.” Proceedings of the 48th annual ACM Southeast Conference. 2010. ↩︎
Next Generation Post Processing in Call of Duty: Advanced Warfare, by Jorge Jimenez ↩︎